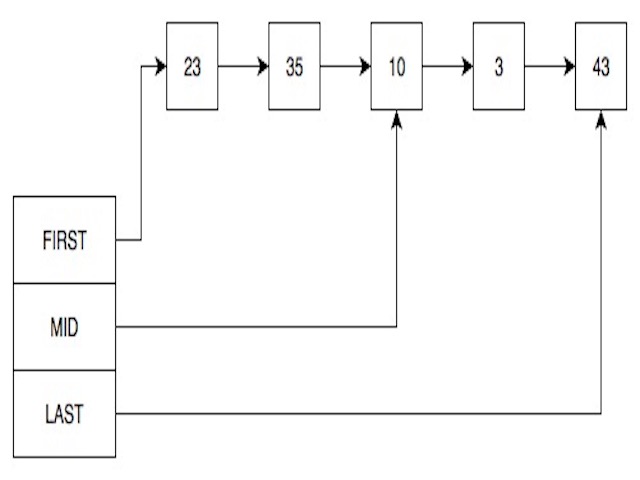
Fig. 1 depicts an index table used for retrieving the first, last, and mid elements quickly. This post is primarily about singly linked lists and how search speed can be improved through indexing.
Definitions
Linked List: A logically connected sequential list of items. Logical connections are defined by pointers from each node to the next — the power is in the dynamic structure.
Indexing: A way to optimize data access by maintaining a separate lookup table that points to key positions in the list. Borrowed from databases, it allows skipping large portions of the list during a search.
The Core Idea
We can improve search speed by assigning each node an ordered ID. Given ordered IDs, we maintain a small index table pointing to selected nodes. During a search, we compare the target ID against the index table to determine which segment of the list to scan — skipping everything else.
Indexing Methods
- Uniform Indexing
- Clustered Indexing
- Multi-level Indexing
- Indexing using series
Uniform Indexing
Adds an index entry after every k elements. Simple and effective for static lists where
we can precompute the optimal k. In practice, linked lists are dynamic — insertions
and deletions shift the distribution — which limits the value of a fixed stride.
Clustered Indexing
Groups elements by shared properties and indexes the clusters. Good in theory, but the challenge is defining a clustering function that remains useful as the list evolves over time.
Multi-level Indexing
Creates a hierarchy of index tables — an index over an index. This can yield very fast searches, but development complexity grows with the number of levels. More on multi-level indexing at CMU.
Indexing Using Series
Uses a mathematical series (Fibonacci, powers, etc.) as the basis for choosing index positions. This exploits the properties of the series to achieve fast search with minimal implementation complexity. The approach is covered in detail in this paper: Speeding Up Search in Singly Linked List Using Series.
Back to Blog